

本文是直接复制粘贴我在Linux.do发布的文章
在服务器上部署了一个n8n,就想找几个项目部署学习一下,找到了L站的一个自动推送每日热门贴的教程
【n8n系列教程6】十分钟完成:每日AI总结L站热门贴,并自动推送到你的邮箱
觉得非常不错,但是复制下来后发现和很多帖子下最近的回复遇到的问题一样,rss请求失败了,状态403,问了chatgpt说是cloudflare给拦截了,于是尝试解决
首先介绍环境,我的服务器是部署在美东,Debian10,然后用1panel管理后台,n8n和其他与本文无关的服务都部署在docker中
在经过一天的上班摸鱼之后,为了实现原帖基本一致的功能,我的解决思路和步骤如下(注册了几个月第一次发帖,另外原理部分有很多chatgpt生成内容,难免不准确,大佬多指正)
安装warp,启动wireproxy
第一步利用脚本在服务器上安装warp,然后使用它的wireproxy功能,将VPS的请求伪装成来自 Cloudflare 信任区域,避免了 VPS 原始 IP 被 Cloudflare 检测出为 “机器流量” 而封锁。
wget -N https://gitlab.com/fscarmen/warp/-/raw/main/menu.sh && bash menu.sh [option] [lisence/url/token]
warp
13 #选择使用公用账号启动wireproxy
Warp会在我们的服务器上打开一个代理端口给本地服务使用,注意这里最好把vps的各种服务都绑好域名访问然后关闭所有ip访问,不然所有人都可以通过ip:wireproxy端口来使用你的代理服务
但是这还不够,仅仅通过这个代理去获取,依然会返回403,chatgpt教我要用Puppeteer 启动一个Chromium无头浏览器模拟真实用户。puppeteer是 Node.js 的浏览器控制库,它能模拟完整的浏览器环境(包括执行 JavaScript、加载 DOM、cookie/session 等)。启动无头 Chrome,通过设置 user-agent 伪装成桌面用户。能真正渲染页面内容,绕过 Cloudflare 的 JS Challenge、token 校验等。最终从页面 DOM 中提取完整 RSS XML。
编写定时脚本,借助puppeteer抓取rss
这一部分,我的方案不算太优雅但算是易于理解,我在服务器一个目录下新建一个Puppeteer环境,使用puppeteer库的功能再通过wireproxy的代理端口去请求L站的rss,然后编写一个定时脚本获取到信息后转发给我们的n8n,n8n可以通过webhook功能提供一个用于接收请求的url,一旦n8n收到请求就执行原有的处理流程
经过我的测试,二者缺一不可,至少在我的服务器上,必须同时配置wireproxy和puppeteer才能在一个大约十多分钟一次的频率下稳定获取内容
以下是我使用的脚本示例和操作流程
首先如果没有,先安装npm和nodejs
# Debian/Ubuntu 系统示例
apt update
apt install -y curl
curl -fsSL https://deb.nodesource.com/setup_18.x | bash -
apt install -y nodejs build-essential
然后编写抓取脚本
mkdir -p /home/rss-collector # 随便找个地方
cd /home/rss-collector
npm init -y
npm install puppeteer
来自gpt的一些注释:执行 npm install puppeteer 会自动下载一个 Chromium 二进制,体积大约在 150MB 左右。如果你想使用系统自带的 Chrome/Chromium,也可以安装 puppeteer-core,并手动指定可执行路径,但为了演示简便,这里直接用默认的 Puppeteer。
在文件夹中创建fetch_rss.js
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: true,
args: [
'--no-sandbox',
'--disable-setuid-sandbox',
'--proxy-server=socks5://127.0.0.1:54321', // 修改为你的 SOCKS5 代理端口
],
});
try {
const page = await browser.newPage();
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) ' +
'AppleWebKit/537.36 (KHTML, like Gecko) ' +
'Chrome/114.0.0.0 Safari/537.36'
);
await page.goto('https://linux.do/top.rss?period=daily', {
waitUntil: 'domcontentloaded',
timeout: 60000,
});
const maxWait = 30000;
const start = Date.now();
let xmlText = '';
while (Date.now() - start < maxWait) {
await new Promise(res => setTimeout(res, 1000));
const text = await page.evaluate(() => document.documentElement.textContent);
if (text.includes('<rss')) {
xmlText = text.trim();
break;
}
}
if (!xmlText) {
console.error('Error: 未能在 30 秒内拿到 RSS XML,请检查网络或 WARP 配置');
process.exit(1);
}
console.log(xmlText);
} catch (err) {
console.error('抓取 RSS 失败:', err.message);
process.exit(1);
} finally {
await browser.close();
}
})();
接下来使用crontab或者或者我是用1Panel侧栏的计划任务功能创建了一个定时的脚本,运行刚才的代码,然后把抓取到的信息发送到webhook url,这个我们在之后的n8n配置中会方便的获取到
#!/bin/bash
WEBHOOK_URL="https://heiheihei/workflow/12345"
TEMP_FILE="(mktemp)"
cd /home/rss-collector
# 执行 JS 脚本并写入临时文件
node fetch_rss.js>"TEMP_FILE"
# 如果输出为空或文件太小(小于 5000 字节),则退出
if [[ ! -s "TEMP_FILE" ||(stat -c%s "TEMP_FILE") -lt 5000 ]]; then
echo "[WARN] RSS 内容可能不完整或为空,跳过发送"
cat "TEMP_FILE"
rm "TEMP_FILE"
exit 1
fi
# 调用 Webhook
curl -X POST \
-H "Content-Type: application/xml" \
--data-binary "@{TEMP_FILE}" \
"{WEBHOOK_URL}"
rm "TEMP_FILE"
然后我们去n8n上,修改一下原有的流程
首先就是要把原来的定时启动+rss获取改成webhook启动

双击webhook节点可以找到要填写给服务器脚本的url,记得选择production的url,这样设置就全部结束了,定时脚本在服务器启动时,会运行js程序,使用puppeteer库的功能,在wireproxy的代理端口下获取rss内容,然后通过webhook全部发送到n8n,接受进一步的处理和推送
要注意,rss获取间隔时间不要过短,我的测试下,服务器两次请求的间隔要至少超过10分钟,不然怎么都会被拒绝
修改workflow,处理数据
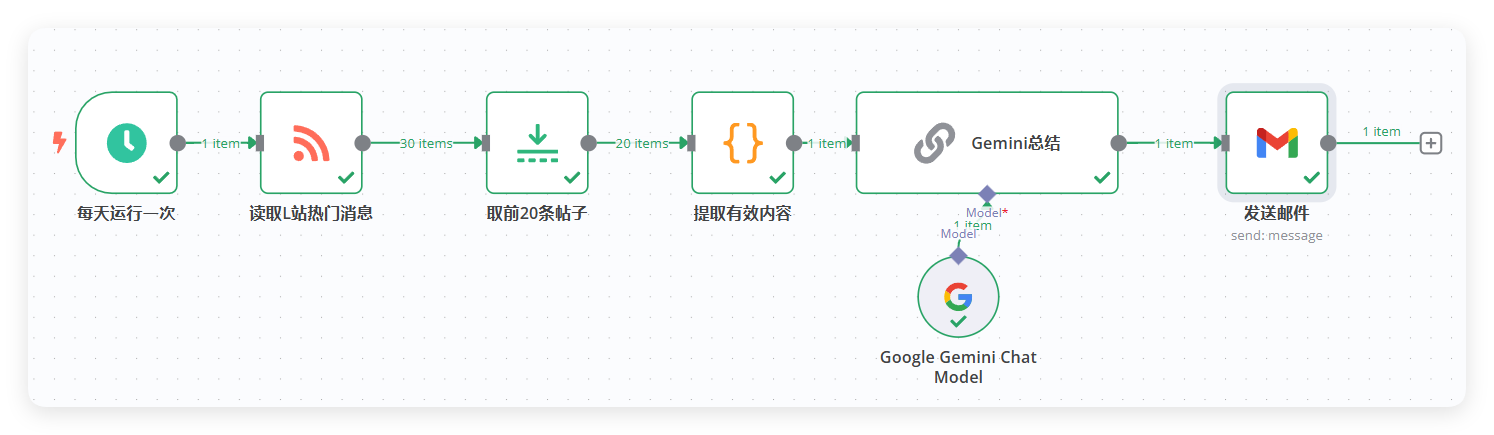
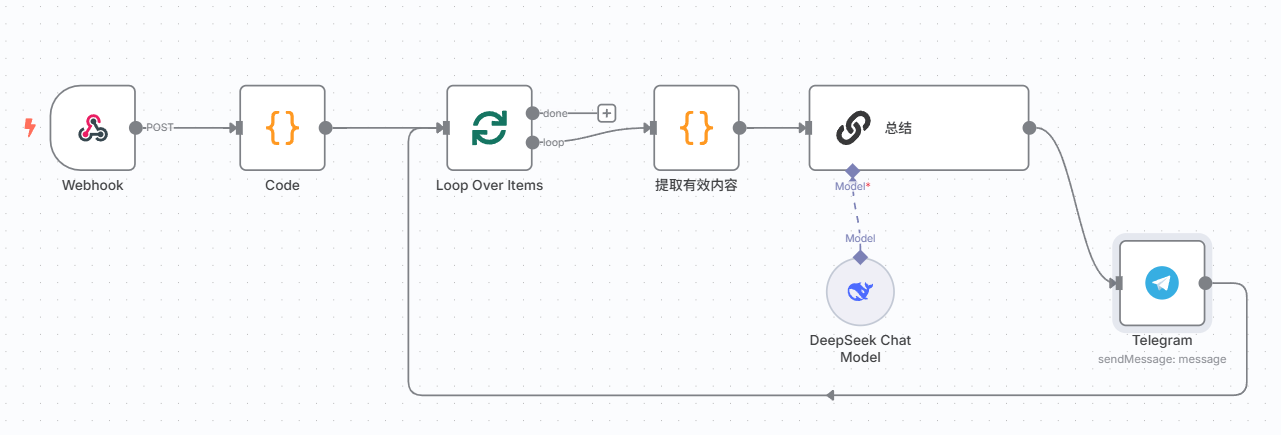
以上是原帖workflow和我当前使用的workflow对比
我对工作流程做了一些修改,首先原贴使用的触发器被我们换成了webhook,然后获取到的数据因为不再是rss自动分好类的json格式,所以我们加一个code节点只保留我们需要的信息
return $input.first().json.body.rss.channel.item
本来以为处理会复杂一点就用了code节点,然后发现好像完全不用处理,总之已经动起来了,不想再改了
接下来原贴筛选了前20个帖子然后扔给Gemini去做总结,我换成了deepseek但是经常会碰到输出上限,所以我用了循环节点,每10个为一组交给deepseek处理一遍,然后直接发送到telegram节点让它发送文本消息给我
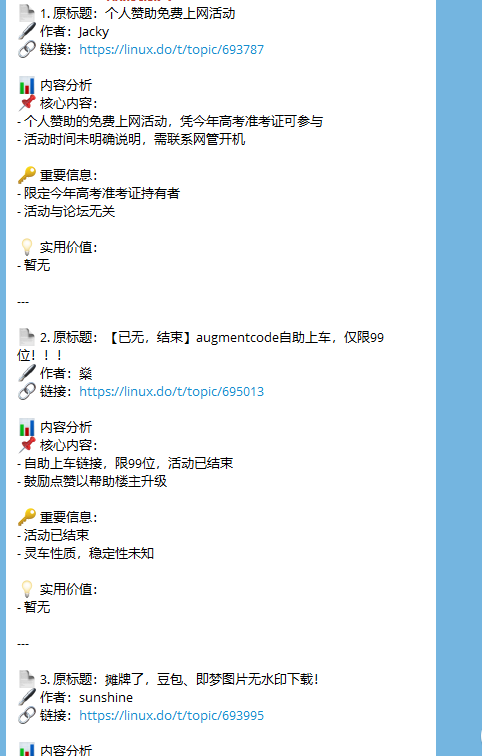
以下是我的workflow配置
{
"name": "My workflow 3",
"nodes": [
{
"parameters": {
"text": "={{ json.text }}",
"additionalFields": {}
},
"type": "n8n-nodes-base.telegram",
"typeVersion": 1.2,
"position": [
1220,
-60
],
"id": "1409a08f-10a1-481f-a272-107ef5ab31f1",
"name": "Telegram",
"webhookId": "7e9fead9-3c29-4701-8b7b-007ba59ff550",
"credentials": {
"telegramApi": {
"id": "vr462TaGdGAshRnc",
"name": "Telegram account"
}
}
},
{
"parameters": {
"batchSize": 10,
"options": {}
},
"type": "n8n-nodes-base.splitInBatches",
"typeVersion": 3,
"position": [
440,
-240
],
"id": "3ec88aae-cc26-4db4-8450-22dff234a42d",
"name": "Loop Over Items"
},
{
"parameters": {
"promptType": "define",
"text": "=以下为L站的帖子的内容\n{{json.text }}",
"messages": {
"messageValues": [
{
"message": "⸻\n\n你是论坛内容分析助手。针对每篇帖子,请严格按以下格式输出:\n\n📄 <序号>. 原标题:<帖子标题> \n🖋️ 作者:<作者名> \n🔗 链接:<原链接> \n\n📊 内容分析 \n📌 核心内容: \n- 用简洁的几个句子全面概括相应帖子内容 \n\n🔑 重要信息: \n- 关键点1 \n- 关键点2(如有可加第3点)\n\n💡 实用价值: \n- 提取可操作的信息(如有,无则写“暂无”) \n\n\n⸻\n\n处理原则:\n\t•\t保持简洁,避免冗长\n\t•\t突出实用性内容\n\t•\t如涉及资源,标注使用条件\n\t•\t如涉及技术,标注关键参数\n\t•\t输出格式统一,便于Telegram中阅读\n\t•\t不添加 Markdown 或 HTML 代码标识(如 ```)\n"
}
]
}
},
"type": "@n8n/n8n-nodes-langchain.chainLlm",
"typeVersion": 1.4,
"position": [
860,
-240
],
"id": "74e73921-1ae4-4052-b768-bc9d06669b32",
"name": "总结",
"retryOnFail": true,
"notesInFlow": true
},
{
"parameters": {
"jsCode": "return input.first().json.body.rss.channel.item"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
200,
-240
],
"id": "7551e1e5-7885-42a4-814b-669c56dc41d3",
"name": "Code",
"alwaysOutputData": false
},
{
"parameters": {
"jsCode": "const items =input.all();\nlet text = \"\";\n\nitems.forEach((item, index) => {\n const creator = item.json['dc:creator'];\n const title = item.json.title;\n const link = item.json.link;\n\n const rawDescription = item.json.description || \"\";\n const plainText = rawDescription.replace(/<[^>]+>/g, '');\n const snippet = plainText.match(/[\\u4e00-\\u9fa5,。!?、;:“”‘’《》【】()——…]/g)?.slice(0, 150).join('') || '';\n\n const contentSnippet = snippet;\n\n text += `第{index + 1}篇帖子标题:{title} \\n 第{index + 1}篇帖子作者:{creator} \\n 第{index + 1}篇帖子链接:{link} \\n 第{index + 1}篇帖子内容:{contentSnippet} \\n\\n`;\n});\n\nreturn {\n text: text.trim()\n};"
},
"type": "n8n-nodes-base.code",
"typeVersion": 2,
"position": [
680,
-240
],
"id": "c7f37a68-f22b-4fe7-938f-60ef6a0b0fd8",
"name": "提取有效内容",
"retryOnFail": true
},
{
"parameters": {
"options": {}
},
"type": "@n8n/n8n-nodes-langchain.lmChatDeepSeek",
"typeVersion": 1,
"position": [
880,
-40
],
"id": "2cc954cc-eacf-4b21-84ae-497e39cfeebc",
"name": "DeepSeek Chat Model",
"credentials": {
"deepSeekApi": {
"id": "jdhbDrz31BQ43DZT",
"name": "DeepSeek account"
}
}
},
{
"parameters": {
"httpMethod": "POST",
"path": "get_linux_do",
"options": {}
},
"type": "n8n-nodes-base.webhook",
"typeVersion": 2,
"position": [
-20,
-240
],
"id": "5256dfa1-7ee8-428b-b9c9-fbf17a45ede3",
"name": "Webhook",
"webhookId": "8a525c47-db6a-40e0-b5d5-fad89f13096e"
}
],
"pinData": {},
"connections": {
"Telegram": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"Loop Over Items": {
"main": [
[],
[
{
"node": "提取有效内容",
"type": "main",
"index": 0
}
]
]
},
"总结": {
"main": [
[
{
"node": "Telegram",
"type": "main",
"index": 0
}
]
]
},
"Code": {
"main": [
[
{
"node": "Loop Over Items",
"type": "main",
"index": 0
}
]
]
},
"提取有效内容": {
"main": [
[
{
"node": "总结",
"type": "main",
"index": 0
}
]
]
},
"DeepSeek Chat Model": {
"ai_languageModel": [
[
{
"node": "总结",
"type": "ai_languageModel",
"index": 0
}
]
]
},
"Webhook": {
"main": [
[
{
"node": "Code",
"type": "main",
"index": 0
}
]
]
}
},
"active": false,
"settings": {
"executionOrder": "v1"
},
"versionId": "bcb435f2-3786-4868-a45f-377d1393e35c",
"meta": {
"instanceId": "d2e350b020eeb7d7ff5013e930bd912332ba24b773f76a1d9c1c49cd85ec83c2"
},
"id": "LYZXNsuh0UGuVaR0",
"tags": []
}
另外说一下,telegram的credential
简单说一下流程供参考
先找@BotFather去注册一个机器人,拿到token填在n8n获取到credential,然后要创建一个公开频道,把这个bot拉进来作为管理员,在n8n的telegram节点会需要一个chat id,是你的机器人要发言的频道或群组的chat id,获取方式是进入网页端telegram,打开那个频道,地址栏最后的包括‘-’符号的一串数字填写进去
debug思路
我觉得过程中不遇到bug是不太现实的,我把每一步可能遇到的问题和解决思路简单总结一下
- 安装Warp:SSH服务器控制台输入warp,确认wireproxy已经开启别记错端口
- 编写完js代码后可以直接运行一下,node ./fetch_rss.js,如果有依赖库没装记得装一下
- 脚本记得两次运行之间至少间隔10分钟,不然一定抓不到(至少我的服务器上
- 如果怀疑已经请求成功,是n8n接受不到消息,可以本地或服务器本地用curl工具测试一下,当然也别忘记打开workflow开关
Comments NOTHING